
Mystery of Incorrect Sprint Reports

With just one day remaining to submit her sprint reports to the Executive team, Sharon is pinned to the screen and trying hard to make sense of all the messed up numbers in the sprint reports. The burn down chart, version report etc are showing inconsistencies which were not expected. Incorrect numbers means the incorrect release information, incorrect reporting in velocity etc.
Sharon is the Atlassian toolsmith responsible for the Jira app at her organization. With almost 720 active users Sharon manages approximately 200 Jira projects which cover Project customization, configuration tweaks, Reporting etc.
After a lot of investigation, Sharon uncovers a pattern where she sees a lot of issues were updated with wrong field values, most probably ‘bulk update’ gone wrong. With no easy way to track changes Sharon goes through the history of a few tickets and notices Pete was the one who changed the fields such as ‘Story points’, ‘Sprint’, ‘Status’ etc.
Immediately she recalls her 2 months old conversation with Pete, IT admin & co-owner of Jira who left the organization last week after an internal dispute with management.
Pete - Hey Sharon, we are on Jira cloud so we don't need data backups, correct?
Sharon - No, it's not true. We do need to backup Jira as per Atlassian’s policy (SaaS Shared Responsibility Model). In fact we do use native Jira exports for backups and the exported data is stored on our NAS server.
Pete - Wow I didn’t know that! So what if these exports are not accessible?
Sharon - Then we won't be able to recover the data in case of disaster.
Pete - That's risky, let's secure our NAS so we have these export files when we need.
Sharon, now regaining her senses and thinking of the worst case scenario, logs in into the NAS share to check the export files. Her nightmare comes true, no export files… it's gone. She somehow manages to find one copy of the export file on her local machine but soon she realises that she cannot revert the entire site to an older state as it will have even bigger data loss impact.
Data protection challenges faced by Jira admins
Jira admins have been facing data consistency issues due to several reasons, be it accidental or malicious events. Commonly, Jira admins have reported the following scenarios of data corruption which keep them awake at night.
- Lack of data protection strategy & awareness
- Learn more about
- Merger of Jira sites due to M&A, company restructuring etc
- Migration from on premise Server to Cloud version of Jira
- Jira cloud instance cleanup
- Human error in daily administration & operations - Incorrect updates to individual issues or bulk updates.
- Disgruntled employees deleting or updating Plans, Epics, Stories, Tasks & Attachments
- Malicious attacks
- Bad data seeding & replication in Sandbox resulting in poor testing
How can Revyz help?
Reverting the issues to the previous state is one common problem admins come across very often. With increasing customer feedback, we released the first version of ‘Revert issues’ last week.
Benefits of ‘Revert Issues’ feature
- Revert existing issue to its previous state
- Rollback field values as it used to be from available snapshot
- Recovery from Malicious insider/outsider’s actions
- Recovery from accidental updates
- Detailed logs to track restore changes
How does the ‘Revert Issues’ feature work?
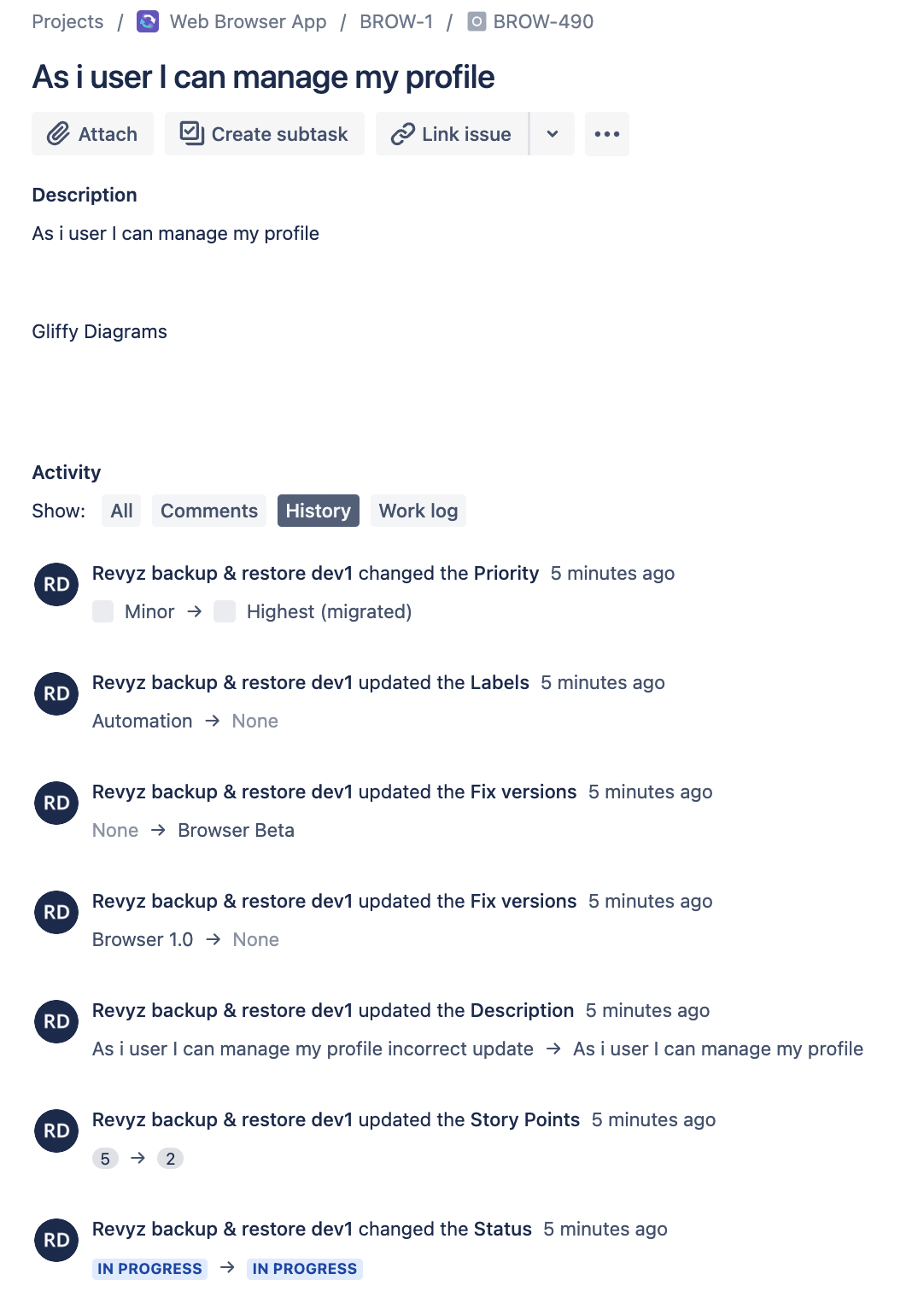
- TIS-84 was modified unintentionally and is to be reverted back from snapshot.
- Unwanted changes done to BROW-490
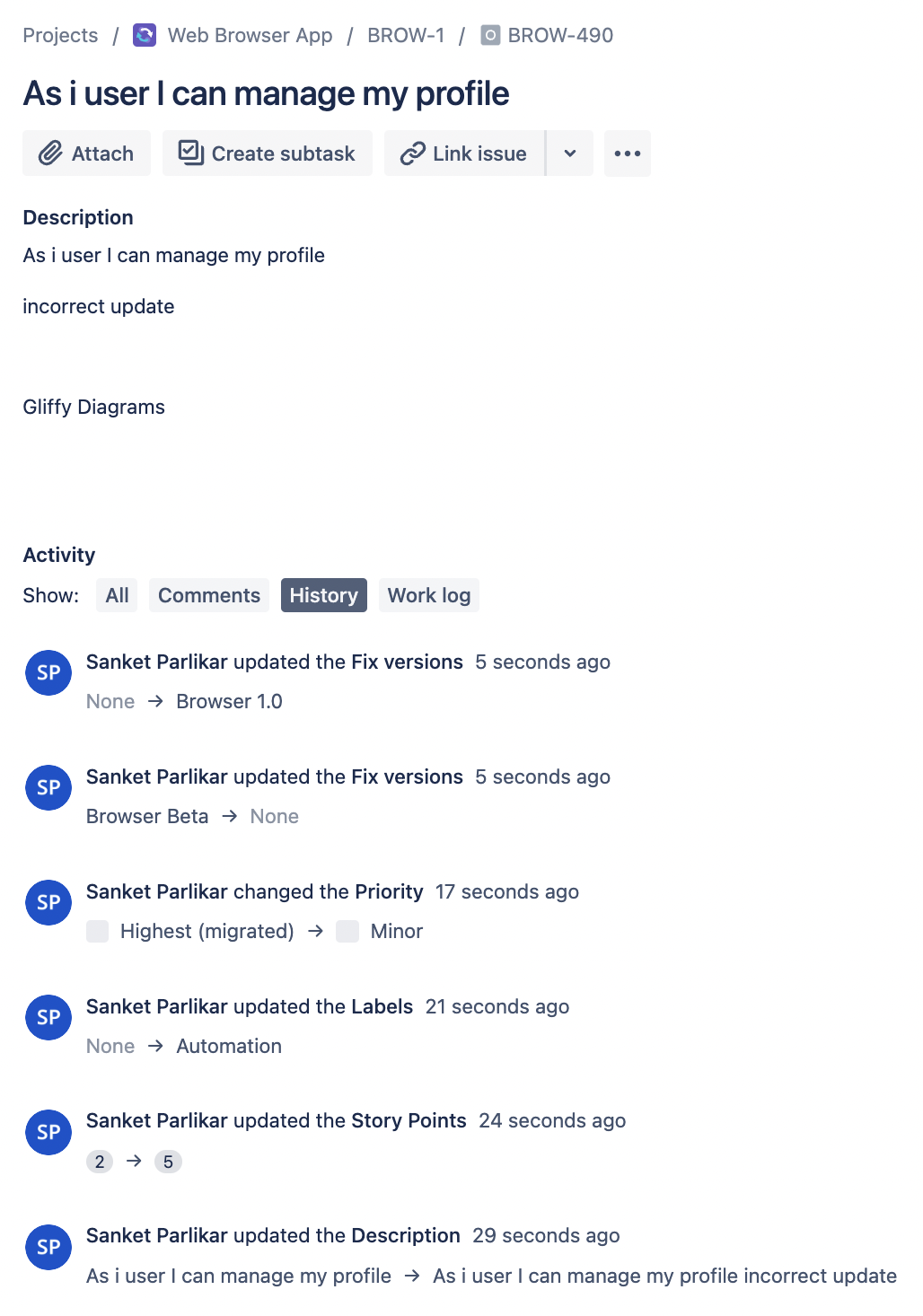
- To revert the issue, go to Revyz app -> Restore -> Advance Restore .
- Select ‘Revert issues’ under “data recovery action’ and fill all other filters.
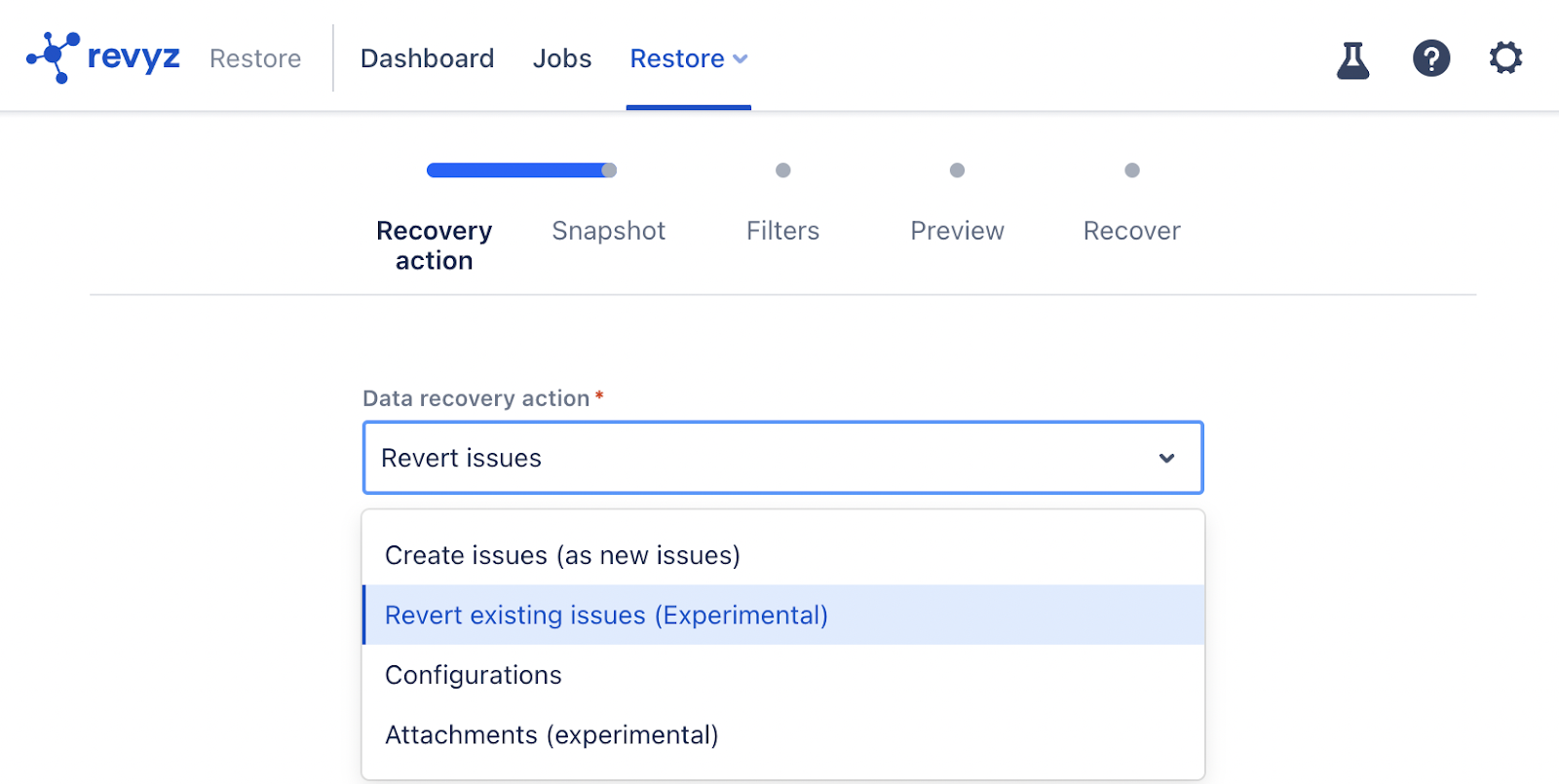
- Select BROW-490 from snapshot and restore
- Issue reverted successfully
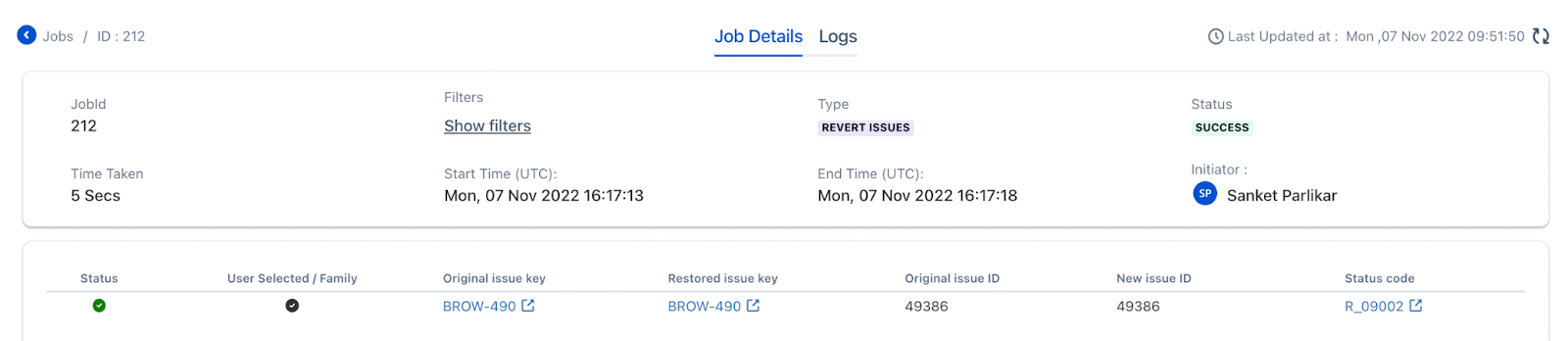
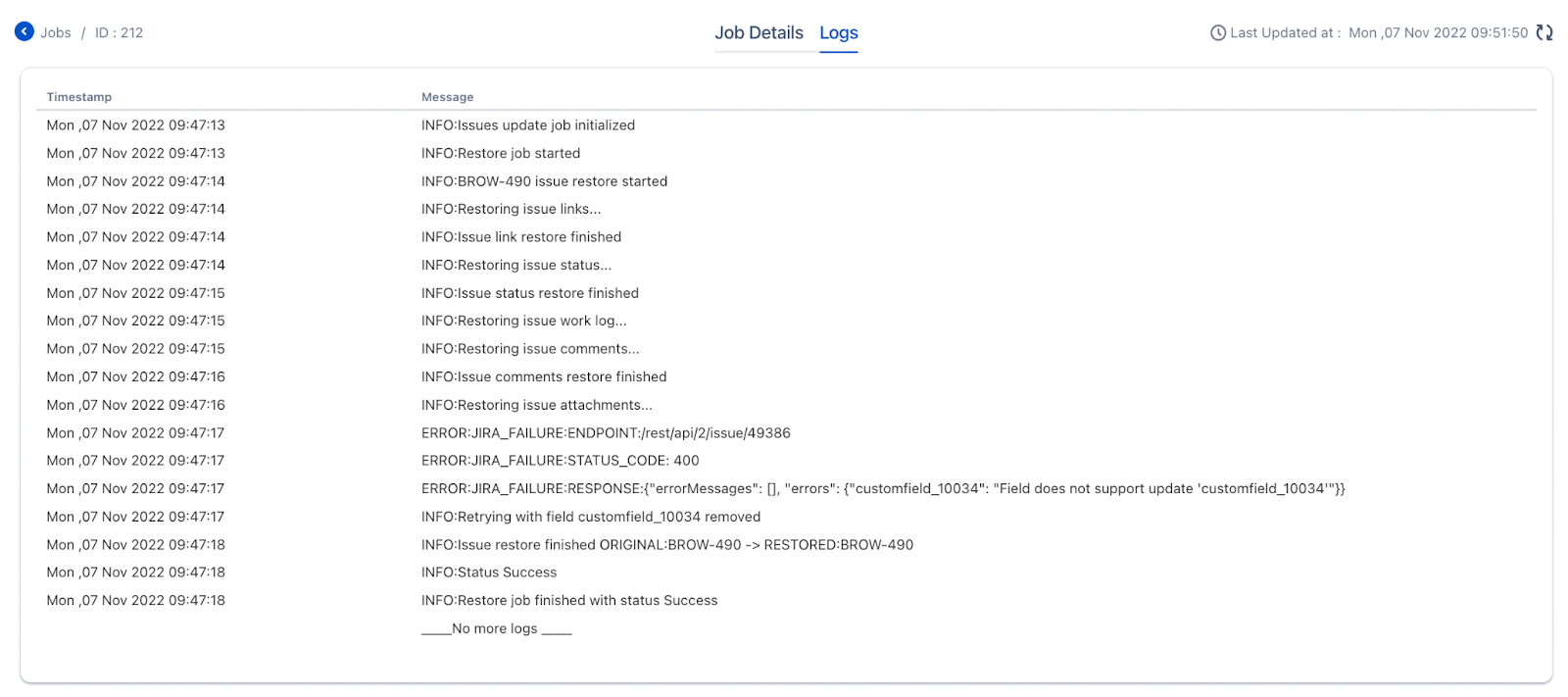
- BROW-490 after reverts all the fields
Conclusion
Implementing Data protection strategy for Atlassian Jira cloud has become a necessity and equally complex. With limited native options from Atlassian, you will have to either build some custom scripts, manage data on your own to address your data protection needs or you leverage 3rd party SaaS applications such as Revyz to offload data protection from your core IT team.
Revyz Backup & Restore app for Jira can store data securely & remotely, making it available for various recovery scenarios without having you to rollback the entire site.
Try Revyz for free - Atlassian marketplace link. Share your feedback on how we can improve & what other use cases you would want Revyz to address.
.
Blogs from Revyz
Atlassian Data Protection - Challenges in the Cloud
7 Reasons Why A Jira Backup & Restore Solution Is A Must Have
Pro’s and Con’s of using Jira Cloud Database Backup & Restore
Mystery of Incorrect Sprint Reports
Jira - Restoring Issue Family Hierarchy
SaaS Backup: An Antidote to Ransomware
Data Backup - A Key Pillar of Insider Risk Management
What’s your Atlassian Cloud Migration & Data Protection Strategy?
A Guide to SaaS Shared Responsibility Model
Why you need a SaaS backup strategy and solution
Why we built Revyz
