

Jira - Restoring Issue Family Hierarchy
Atlassian Jira Cloud plays a vital role in modern businesses, offering a simple setup process and enabling streamlined work management workflows. While it was initially developed as a bug and issue-tracking tool, Jira has evolved to support a wide range of use cases, including Agile team tools, project management, product management, process management, and task management.
This versatility makes Jira an invaluable tool for IT teams to address the diverse needs of internal customers within a single platform. However, while Jira solves many challenges, it also introduces complexities in managing the system and its associated data.
Data protection challenges faced by Jira admins
Jira admins have been facing data consistency issues due to several reasons, be it accidental or malicious events. Backup Jira cloud solutions help mitigate these risks by providing reliable recovery options for any unexpected data loss or corruption. Commonly, Jira admins have reported the following scenarios of data corruption that keep them awake at night.
-
Lack of data protection strategy & awareness
-
Learn more about the SaaS Shared Responsibility Model
-
Merger of Jira sites due to M&A, company restructuring, etc.
-
Migration from on-premise Server to the Cloud version of Jira
-
Jira cloud instance cleanup
-
Human error in daily administration & operations - Incorrect updates to individual issues or bulk updates.
-
Disgruntled employees deleting or updating Plans, Epics, Stories, Tasks & Attachments
-
Malicious attacks
-
Bad data seeding & replication in Sandbox, resulting in poor testing
One of the admins I spoke to told me that during the merger of Jira sites, a lot of existing Epics were impacted due to configuration changes. First of all, there was no clear way to identify the blast radius. Beyond that, there was no way to perform a granular restore of the impacted Epics only.
Another incident I heard was that the Jira admin was working on sanitizing the Scrum reports and wanted to update a subset of issues. A few JQL queries were used wherein some filters were incorrect, and overall, the bulk change result was not what he expected. In this situation, he wanted to simply get a second copy of the same Epics from the older snapshots; this way, he could easily compare the fields using JQL before making any changes to the existing issues in production.
From my brief discussion with so many customers and Jira consultants, it became clear that this is not a one-off issue; these things can happen to anyone, in any environment, and it is not that rare at all.

How can Revyz help?
At Revyz, we set out to solve this problem and make life easier for Jira admins. Over the past weekend, we launched an early access restore feature that allows Jira admins to restore a specific issue along with its entire family hierarchy as it appeared in a point-in-time snapshot.
Benefits of the ‘Restore Issue Family’ feature
- Selecting & restoring specific Epics can automatically get you all the Epics & children underneath it.
- Selecting & restoring specific child issues such as Stories or Sub-tasks can automatically create its parent hierarchy without you having to remember and select those issues during the restore process.
- Restore targeted Epics or Issues; no need to revert entire site.
- Shorter restore time due to targeted dataset.
- Verbose job details along with issue key mapping for simplified tracking.
- Verbose logging along with status codes for power users.
Enterprise functionality
Revyz team believes in empowering admins by building a highly customizable product for Enterprise use cases. As part of that philosophy, we have made new settings completely configurable. The ‘Restore Issue family’ settings can be completely tweaked as per your requirements.
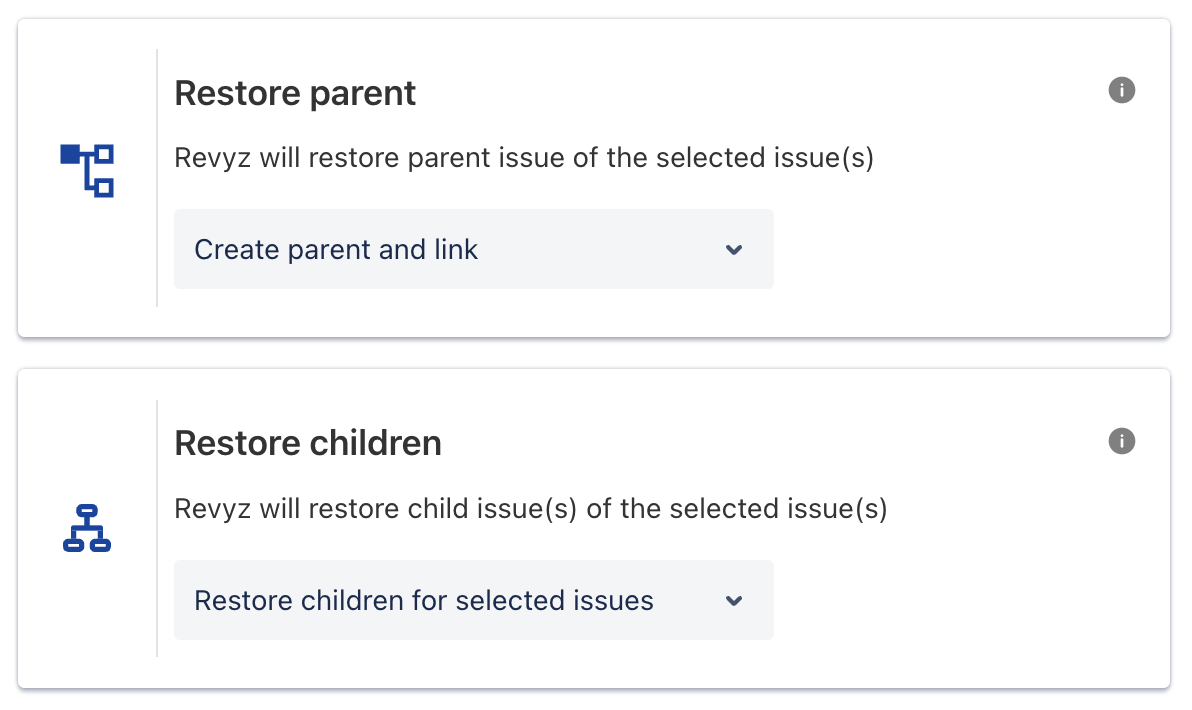
How does the ‘Restore Issue Family’ feature work?
By default, after installing the Revyz Backup & Restore app for Jira, it automatically backs up all issues, projects, and configurations daily.
For example, consider the Epic TIS-2, which has the following issue family hierarchy. This entire hierarchy is backed up daily by Revyz, ensuring comprehensive data protection and easy recovery when needed.

Normally, if you lose TIS-2 along with its associated stories, you are left with the following options. However, given the use case, neither of these may be practical for most customers:
-
Using Revyz: You can restore specific issues, but this requires you to recall the details of all the issues that need to be restored.
-
Using Jira's Native Import-Export Solution:
-
Revert the entire site to an older snapshot to retrieve all the stories in this Epic.
-
This process results in losing recent data.
-
The Solution: Restore Issue Family Feature
With the new ‘Restore Issue Family’ feature from Revyz, you can now define how the restore process manages the issue family hierarchy. Once configured, it can automatically restore all parent and child issues based on the global ‘Restore Settings’ available under Settings.
Steps to restore TIS- 2
-
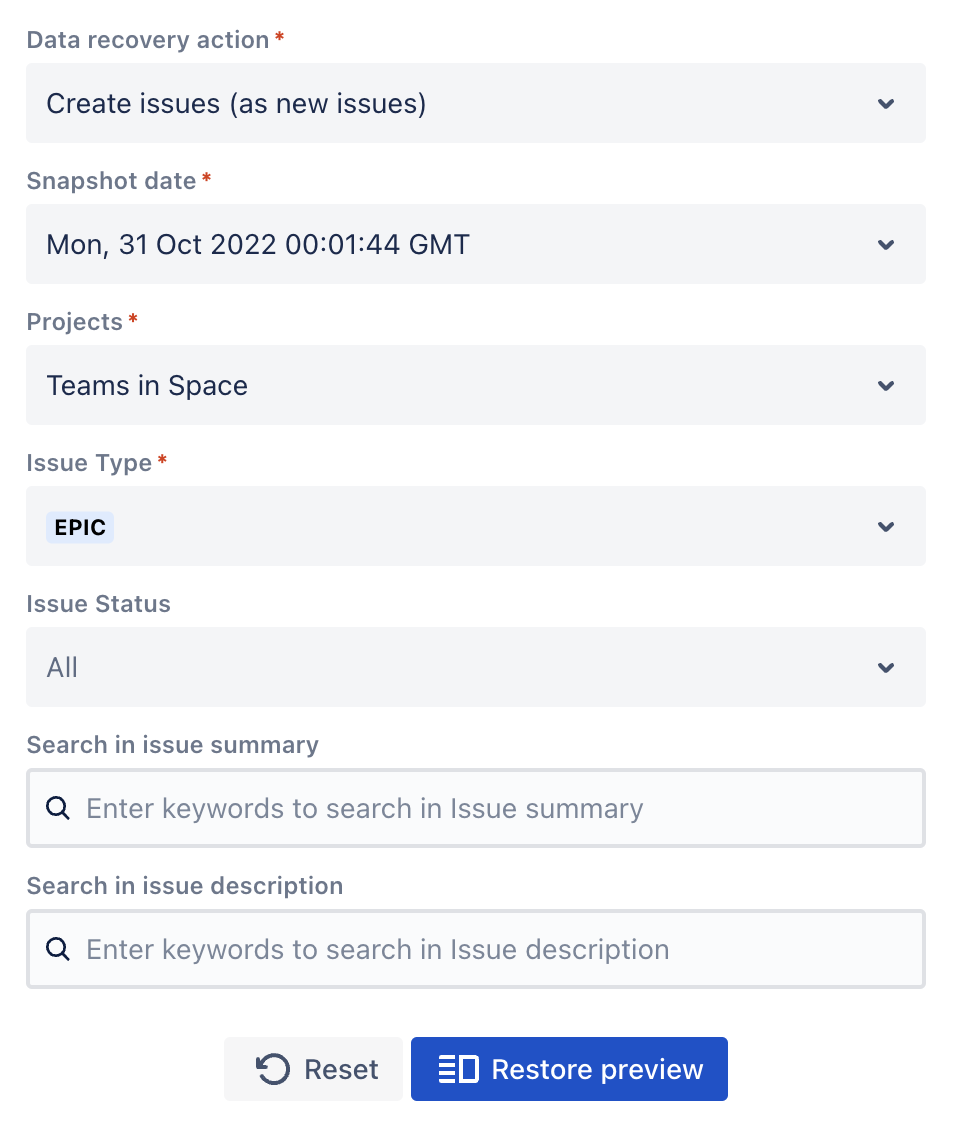
Navigate to Revyz Advanced Restore View.
-
Select Create Issues.
-
Apply relevant filters.
-
Use the Restore Preview option.
-
Select Epic TIS-2 and trigger the restore.
This feature simplifies the process by automatically restoring the entire Epic hierarchy (parent and children) without requiring you to manually recall or select each issue.
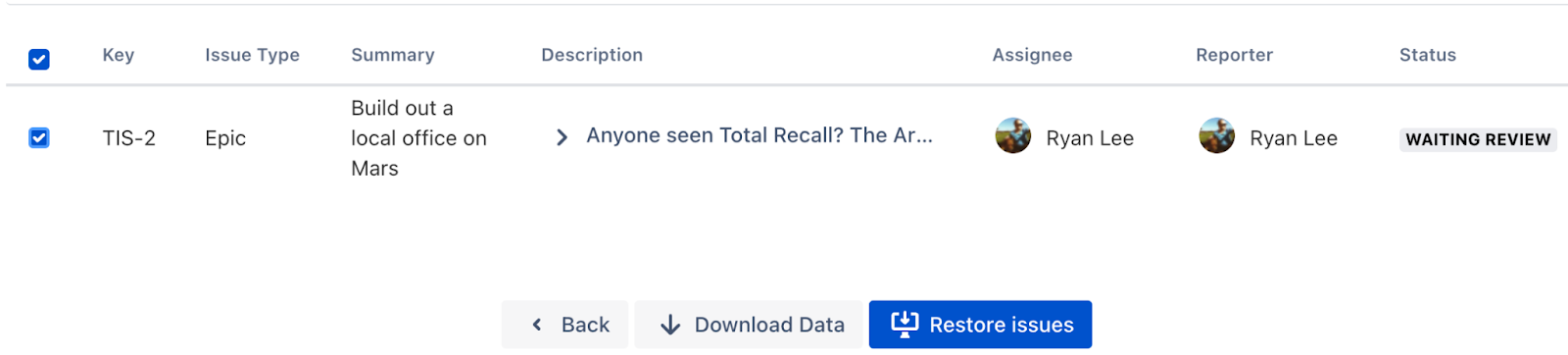
- Once the restore is initiated, the job will look like this:
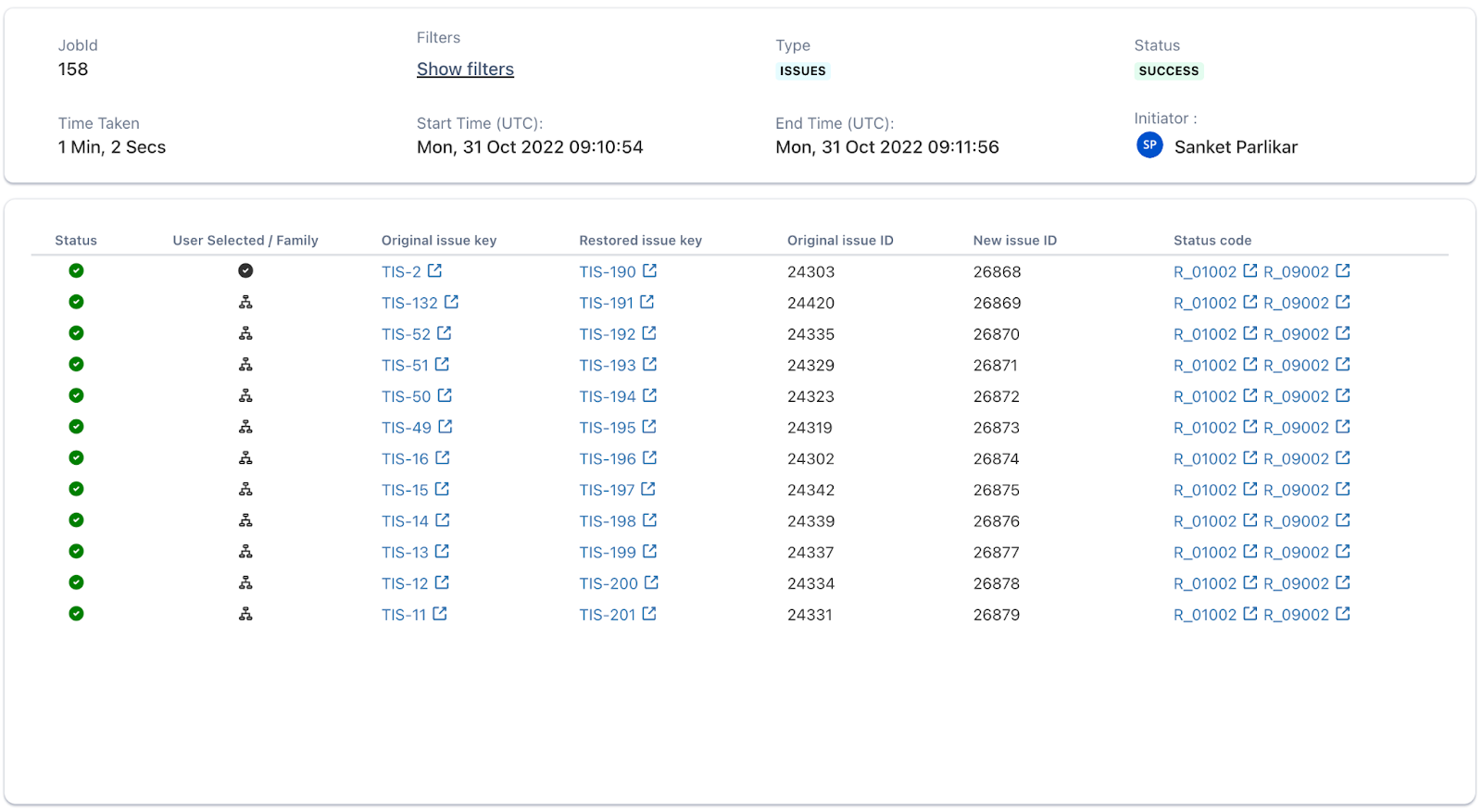
- Here you can see the entire Epic, along with its children, was restored when just Epic was selected for restoration.
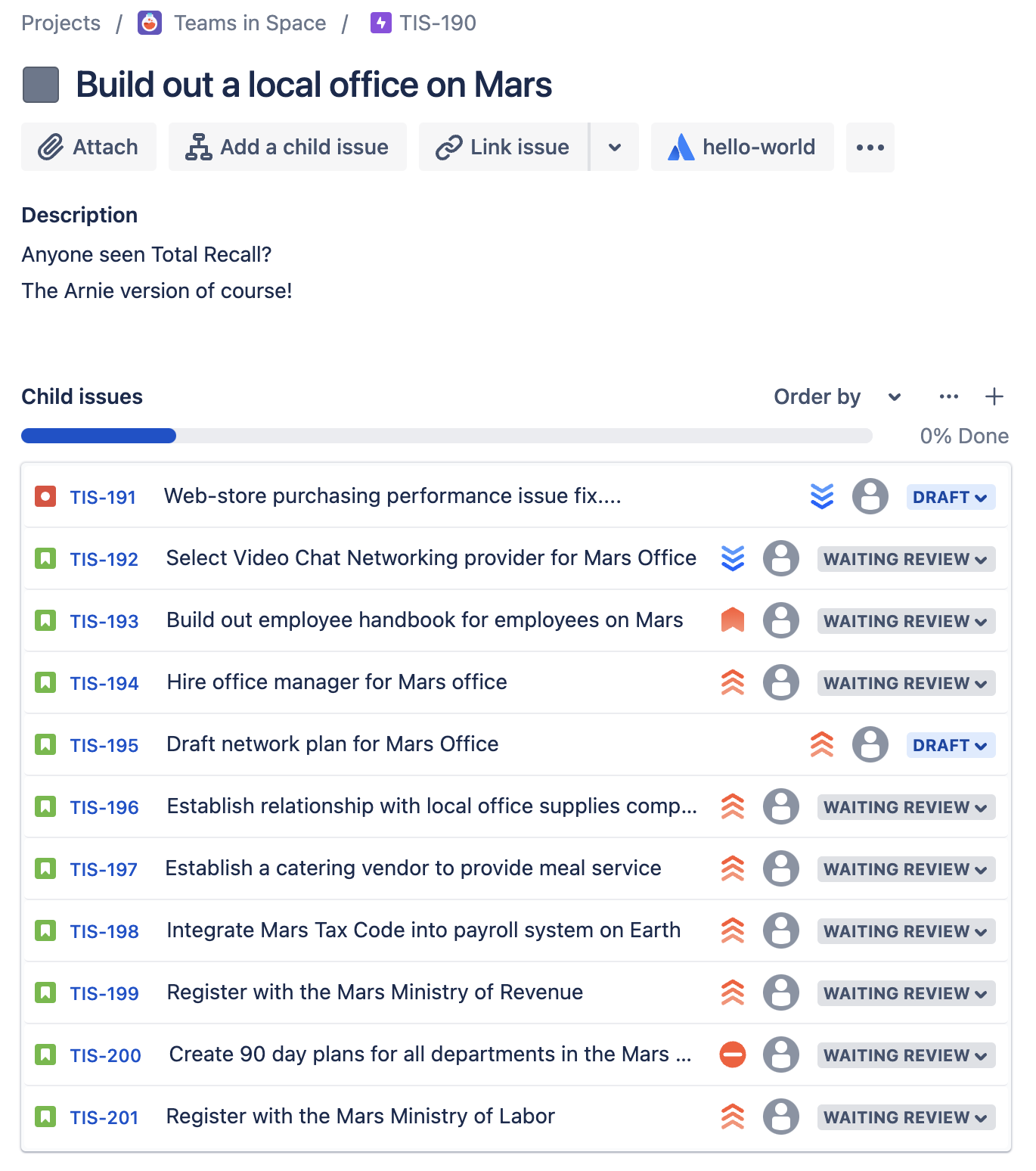
- Similar to the above-mentioned use case, this feature also helps with Child to Parent hierarchy recreation.
Conclusion
Implementing a data protection strategy for Atlassian Jira Cloud has become both essential and increasingly complex. With limited native options from Atlassian, businesses often have to either build custom scripts and manage data protection internally or leverage third-party SaaS applications like Revyz to simplify and offload data protection tasks. The Revyz Data Manager for Jira app securely stores data remotely, making it available for various recovery scenarios without requiring a full site rollback.
This approach not only simplifies data management but also ensures that critical data is protected and easily recoverable. You can try Revyz for free on the Atlassian Marketplace and experience seamless data protection for Jira Cloud. Additionally, we invite you to share your feedback with us on how we can improve and let us know what additional use cases you’d like Revyz to address. Your input will help us tailor our solutions to better meet the evolving needs of Jira users.
Blogs from Revyz
Atlassian Data Protection - Challenges in the Cloud
7 Reasons Why A Jira Backup & Restore Solution Is A Must Have
Pro’s and Con’s of using Jira Cloud Database Backup & Restore
Mystery of Incorrect Sprint Reports
Jira - Restoring Issue Family Hierarchy
SaaS Backup: An Antidote to Ransomware
Data Backup - A Key Pillar of Insider Risk Management
What’s your Atlassian Cloud Migration & Data Protection Strategy?
A Guide to SaaS Shared Responsibility Model
Why you need a SaaS backup strategy and solution
