

Cloud Disaster Recovery Planning : A Step By Step Guide
Part Three of a Multi-Part Series on Disaster Recovery in Cloud
Table of Contents
- Introduction
- Risk Assessment
- Real-World Risks and Examples
- Conclusion
- Jira Disasters Do Happen
- Useful Links and References
Disaster recovery planning is essential for any organization to ensure business continuity and minimize data loss in the event of an unforeseen disaster. Traditionally, these plans were centered around on-premise infrastructure. With the advent of cloud computing, the landscape of disaster recovery has transformed, bringing both new opportunities and challenges.

Introduction
Building a robust cloud disaster recovery (DR) plan is essential for ensuring business continuity and minimizing data loss in the event of a disaster. This article provides a detailed guide to creating an effective DR plan tailored for cloud environments, covering key steps and best practices.
This article delves into the planning process and outlines the key areas that you need to consider when creating your own disaster recovery plan for your cloud.
1. Define Your Objectives
Recovery Time Objectives (RTO): Determine the maximum acceptable downtime for each application or system. This sets the timeline for how quickly you need to restore services after a disruption. RTOs are critical for prioritizing which systems to recover first.
Recovery Point Objectives (RPO): Establish the maximum acceptable amount of data loss measured in time. This defines how frequently data backups should occur to minimize data loss. For example, an RPO of one hour means you can afford to lose up to one hour's worth of data.
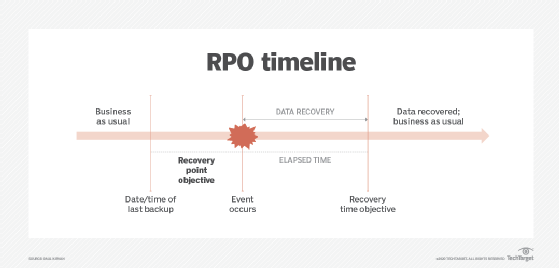
Image source - TechTarget
"These two questions embody the principle between the Recovery Time Objective and the Recovery Point Objective. Alternatively, RTO can be thought of as “How long does it take to restore from a backup,” while RPO asks “How old, at its max, is our youngest backup?”
Rodney Nissen on best practices of backup and disaster recovery in Jira Cloud
TheJiraGuy.com (read the full article)
2. Conduct a Risk Assessment
Assess your cloud environment for potential risks, including cyber threats, natural calamities, internal security breaches, operational mistakes, and human errors. Analyze each risk's probability and consequences to effectively prioritize your protective measures. This risk assessment informs the development of a disaster recovery plan that targets the most critical vulnerabilities. Although precise disaster prediction is challenging, it's wise to rank potential incidents based on their likelihood of occurrence.
Tip: Atlassian Solution Partners are a great place to go when are assessing risks - they see a huge array of cloud scenarios and are an excellent resource to get advice from in the early stages of your Cloud Disaster Recovery Planning process. Click here for a list of solution partners who we trust to work with you in disaster recovery planning
Real-World Example: AWS has experienced numerous outages due to natural disasters, technical errors, and configuration issues, highlighting the importance of preparing for diverse risks (DataCenterKnowledge, source).
3. Inventory Your Resources
Create a comprehensive inventory of all your IT cloud assets, including applications, data, and cloud vendors. Document dependencies between systems to understand the impact of a potential failure on other components. This inventory will help identify critical systems that need priority in a disaster recovery scenario.
Note: For Atlassian Cloud customers, we are building a definitive inventory list that we will publish in coming weeks so make sure that you are following us.
4. Choose the Right Cloud DR Strategy
Backup and Restore: Regularly back up data to a secure cloud location. This is a cost-effective approach but may result in longer recovery times. Suitable for non-critical systems.
Pilot Light: Maintain a minimal version of your environment that can quickly scale up in case of a disaster. This balances cost and recovery speed, making it suitable for critical applications that don't need full replication.
Warm Standby: Keep a scaled-down version of your environment running, ready to take over with minimal downtime. This provides faster recovery at a higher cost, ideal for high-priority applications.
Multi-Site: Run multiple active environments across different locations. This ensures the highest availability and the fastest recovery but comes with significant costs. Suitable for mission-critical applications that require constant uptime.
5. Implement Data Replication
Use cloud provider tools to replicate data across geographically diverse locations. This ensures data availability even if one site goes down. For example, AWS S3 and Azure Blob Storage offer data replication features that can help achieve near-real-time RPOs.
Example: Set up cross-region replication in AWS S3 to automatically replicate data to another region, ensuring that data is always available, even in case of a regional outage.
6. Establish Clear Roles and Responsibilities
Define the roles and responsibilities of your disaster recovery team. Ensure each team member understands their tasks and the overall recovery process. This clarity helps streamline the recovery process during an actual disaster.
Example: Assign roles such as DR coordinator, backup administrator, network engineer, and application specialist, each with specific duties during the recovery process.
7. Develop Detailed Recovery Procedures
Create step-by-step procedures for recovering each critical system. Include instructions for failover, data restoration, and system validation. Ensure that these procedures are easy to follow and accessible during a disaster.
Example: Document the process for initiating a failover to a secondary site, restoring the latest backups, and validating system functionality to ensure everything is running correctly post-recovery.
8. Test Your DR Plan Regularly
Regular testing is crucial to ensure the effectiveness of your DR plan. Conduct simulations and drills to identify weaknesses and make improvements. Use tools like AWS Fault Injection Simulator to test the resilience of your cloud environment without impacting live systems.
Example: Schedule quarterly DR drills that simulate different disaster scenarios, such as data center outages, cyber-attacks, or natural disasters, and evaluate the response and recovery times.
9. Review and Update Your Plan
Regularly review and update your DR plan to reflect changes in your IT environment, new threats, and lessons learned from tests and actual incidents. This ensures that the plan remains relevant and effective.
Example: Update the DR plan annually or whenever there are significant changes to your infrastructure, such as adding new applications or migrating to new cloud services.
Conclusion
Creating a comprehensive cloud disaster recovery plan involves defining clear objectives, conducting thorough risk assessments, and implementing robust strategies for data protection and system recovery. By following the steps outlined in this guide, organizations can enhance their resilience and ensure business continuity in the face of various threats. The real-world examples provided underscore the importance of having a well-documented and regularly tested DR plan. In the next article, we will explore best practices for testing your disaster recovery plan to ensure it remains effective. Stay tuned for more insights and actionable advice.


Useful Links and References
- A government watchdog hacked a US federal agency to stress-test its cloud security
- Fired employee accessed company’s computer 'test system' and deleted servers, causing it to lose S$918,000
- A History of AWS Cloud and Data Center Outages
- A History of Microsoft Azure Outages

