

Recover Automation Rules After Latest Cloud Incident
Background
Call it bad luck, or Murphy's Law, but the leap year will not be a great memory for those responsible for managing the the Atlassian Cloud platform. According to Atlassian's support post (found here), there was a major cloud incident, that at the time of publishing this article, has not been fully resolved.
The Incident : Lost Automation Rules in Configuration
For effected users (and the scope so far seems very wide and far reaching), the simple way to explain the incident is that automation rules inside their Jira sites simply disappeared.
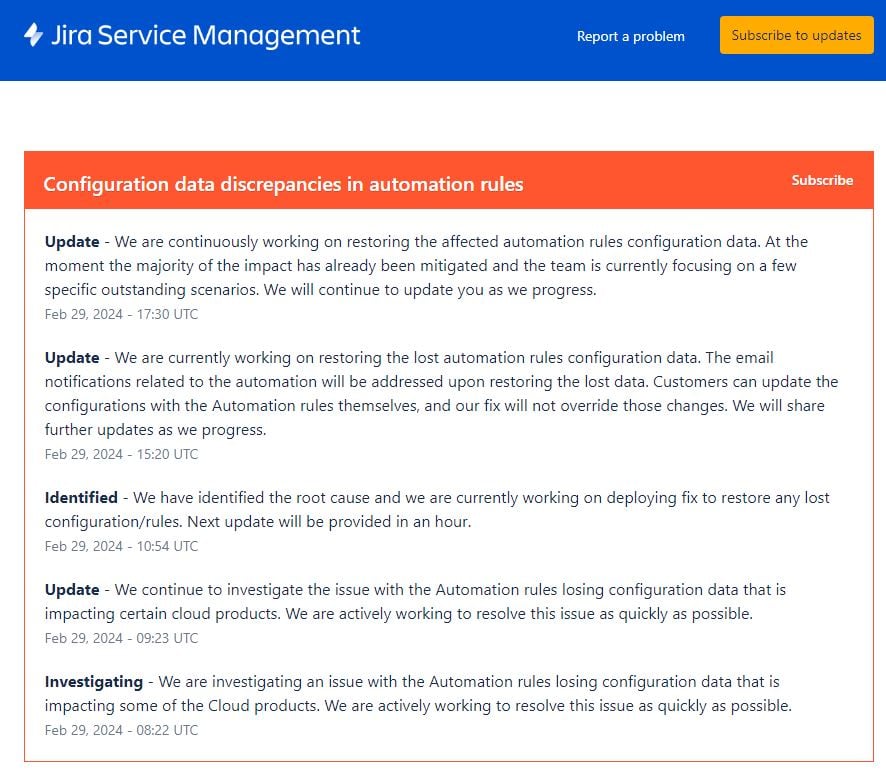
The image below is from the Atlassian Service Status Page as at February 29, 18:00PST. Any Jira Admins should watch this page and subscribe for updates to ensure that you are fully aware of resolution progress and plans by Atlassian : https://jira-service-management.status.atlassian.com/
The impact of this for customers
Automation Rules allow you to automate actions within your system based on criteria that you set. Automation rules are made up of three parts: triggers that kick off the rule, conditions that refine the rule, and actions that perform tasks in your site.
https://support.atlassian.com/cloud-automation/docs/create-and-edit-jira-automation-rules/
As automation rules can be used creatively by Atlassian customers for just about anything, their loss can and will have been having catastrophic impact to customers who are using them for core business processes in their Jira/JSM sites.
Examples of this are;
- Escalation of tickets between people stopping
- Tickets moving between projects no longer happening
- Service desk teams turning up to work to an empty ticket queue
- End-customers not getting notifications and alerts
- Service KPI's around response, comms and resolution times not being met
- Adherence to ITIL practices not being met
How to Recover from this Incident
As an expert in system and data recovery of Jira Cloud, we have been inundated with requests from a variety of Jira sites to help them make a recovery plan and to get their automations recovered and working again.
On March 29th, we invited The expert crew from The Jira Life team of Rodney Nissen, Alex Ortiz and Robert Wen to jump onto a livestream with us to help the Atlassian Community to recover from this incident.
We put the recording of this below and then decided (if you scroll down) to also start this blog page with a section of actionable steps for Jira Admins to take in order to recover as safely as possible and to minimize further business impact.
How to Recover : Livestream with The Jira Life Crew
Advice on How to Recover
Disclaimer: the information in this article is a set of guidelines and ideas and are not based on any inside knowledge of this evolving Atlassian Cloud incident. With that said, the advice below should be taken in general terms and each administrator should take extra care to follow Atlassian's recommendations, to adhere to careful change management processes and if unsure, to defer to your qualified solution partner experts and/or the Atlassian support team.
Talk to Your End Users
This incident has already lasted over one business day so it is clearly significant. It may be that some sites will be effected for a long time so get in touch with your end users and management and;
- Inform them of the outage and of the latest updates from Atlassian
- Ask them specifically for feedback on areas in your operation that are not working. This may help you identify the impact of the issue that you are not yet aware of. You may also glean from the impact analysis feedback ways to work around the issue and to get critical business processes moving again.
- Ask them to inform you if they notice anything changing
- Give them a communications plan of how often that you'll give status updates so that they don't keep chasing you for news
- Review your automations dashboard to see what the blast radius is i.e. which rules were used most and what is the impact of these rules. This information will also drive the prioritization on what to restore back first
If you can restore from backup, do it with care
- Get clear on when the incident started impacting your site - when things are working again, you may have to manually go back and fix data that has 'missed' the workflow.
- If you have backups of your automations, then make a careful plan on whether or not you decide to restore from them and the scope of your restoration.
- Remember, its possible that Atlassian may restore over what you restore so you need to be aware in case that happens
When you restore or rebuild workflows - switch them on one at a time
Each workflow that you restore or rebuild should be turned on individually, and take care to look at dependencies and other factors when you turn a workflow back on. Test each one carefully before switching on another so that you can limit and minimize the impact of any unexpected behaviour.
Make a backup of what you've got - even if its not working
Even if its not working, it is a good practice to make a backup of both your data and your configuration in Jira Cloud before performing any rectification of automations, batch updates to tickets or anything that you are doing to resolve the situation.
Emergency repair jobs sometimes don't go to plan and its great to have a definitive restore point to go back to if data is damaged.
Announcement for Effected Jira AdminsWe have decided to provide free access to our backup and clone tool for Jira Cloud configuration with an included, extended trial of 60 days for any effected Jira Sites. This will enable you to safely and securely back up and protect your Jira Automations immediately. |

|
More Updates Coming
We will be updating this page with more resources, advice and instructions aimed at helping you, so bookmark it and come back to it in future.
More Resources
In a somewhat serendipitous move, Vish Reddy and Stu Lees from Revyz recorded this demo video only two weeks ago.

